引言
文本分类在 NLP 中是一项普遍的任务。它应用范围广泛,从文本分类到客户交谈中检测使用的语言。
举一个日常例子,想象一下你的电子邮件服务的垃圾邮件过滤器——它很可能使用文本分类来保护你的收件箱不受大量不需要的内容的影响。
另一个文本分类的常见用途是情感分析,这是一种自然语言处理技术,用于评估和解释文本中表达的情绪、意见或态度。通过分析所使用的语言,可以确定传达的情感是积极的、消极的还是中性的,从而提供对词语背后的情绪基调或倾向的洞察。
在这篇博文中,我们将构建一个文本分类器来识别推文中的情绪。这是流程:
1、常规NLP与语言模型时代
2、语言模型的简史
3、BERT架构
4、探索数据集
5、BERT中的分词理解
6、BERT的2种不同训练方法
7、错误分析
8、结论与未来研究方向
这篇博客文章将让您通过遵循基本原则构建一个文本分类器,使用像 BERT 家族这样的语言模型。
传统NLP vs 语言模型时代
在这个文章中,我只考虑将语言模型用于文本分类。然而,在硬件有限制或者为了创建一个基础模型的情况下,请考虑使用以下常规的自然语言处理(NLP)方法:
文本分类在自然语言处理(NLP)中扮演着基础支柱的角色,为各种涉及理解和组织文本数据的应用程序提供支持。文本分类的核心是根据文本的内容自动将文本文档划分为预定义的类别或类别。
在传统 NLP 中,分类过程依赖于手工特征和机器学习算法,这些方法往往难以捕捉语言的复杂性和细微差别,特别是对于大型、非结构化数据集。
类似于BERT的语言模型采用基于transformer结构的方式,以更加全面地掌握自然语言的复杂性。
BERT的优势在于其双向性,使其能够通过分析序列中单词的上下文来考虑一个单词的完整上下文。
这个双向理解的上下文允许 BERT 能够:
- 理解细微的细节
- 习惯用语
- 文本中和词语中的上下文含义
在文本表示中,结果更准确、更具有上下文感知性。
语言模型简史
语言模型(LM),对单词序列的可能性进行建模,以预测下一个单词/标记的概率。
LM的研究界可以分为4个阶段:
- 统计语言模型
- 神经语言模型
- 预训练语言模型
- 大型语言模型
统计语言模型
这些是基于马尔可夫假设的词预测统计学习方法的模型。SLM具有固定的上下文长度,通常用’n’表示,也被称为n元模型(二元模型,三元模型等)。
缺点:维度灾难!语言模型的阶数越高,意味着需要准确估计的转换数量呈指数级增长。但研究社区提出了一些想法,如Good-Turing估计,它是一种平滑策略,在一定程度上解决了稀疏性问题。
神经语言模型(NLM)
在NLMs中,过渡概率由神经网络进行估计,如多层感知机或循环神经网络。著名的NLM方法之一是word2vec,它构建一个浅层的神经网络来编码单词表示。
预训练语言模型(PLM)
ELMo是PLMs的前身。由于它使用双向LSTM网络骨干在大量语料库上进行了预训练,因此能够捕捉到上下文相关的词表示。这种结构使得它能够在不需要依赖固定长度的情况下学习词表示。
在经历了短暂的 ELMo 论文介绍期后,Transformer 和自注意力机制被应用于一个语言模型:BERT。
大型语言模型(LLMs)
在扩展 PLMs 的过程中,无论是数据规模还是模型参数,模型能力都会得到提高,并能更好地理解和处理数据中的复杂结构。LLMs 可以完成它们未直接训练的任务(该主题的一篇好文章)。例如,它们在零样本和少样本预测方面表现出色。最著名的例子是 ChatGPT,其架构基于 GPT-3。
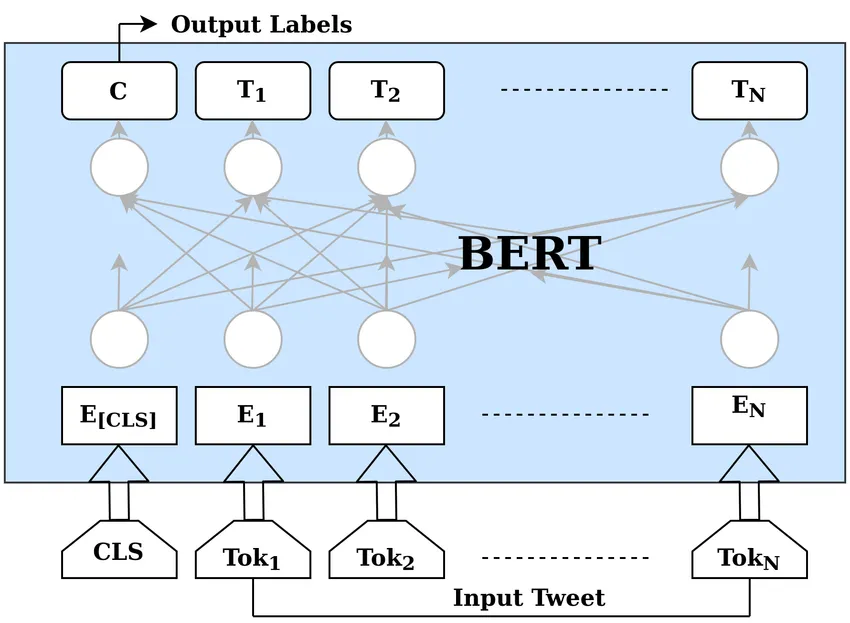
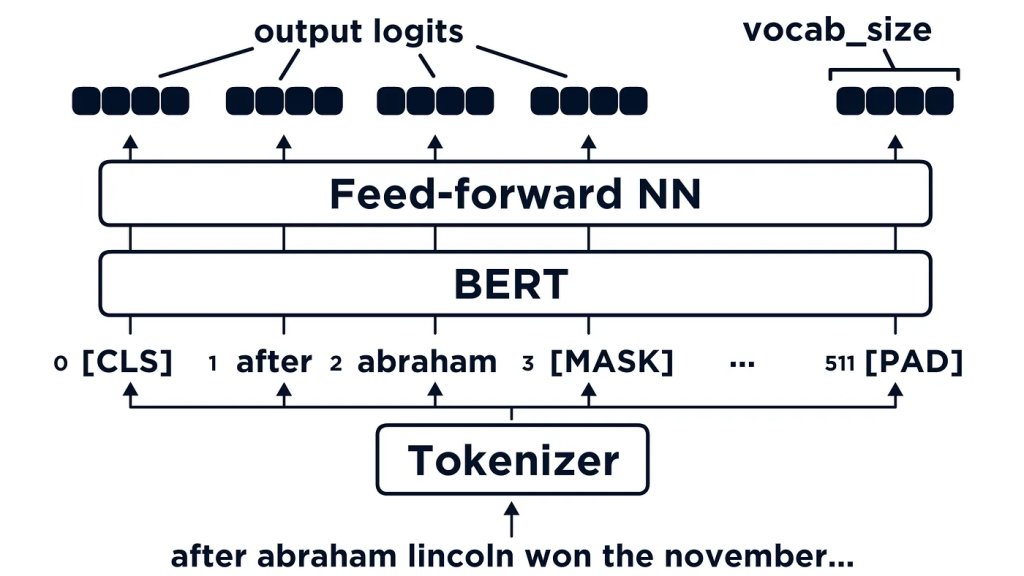
BERT 架构——详细介绍
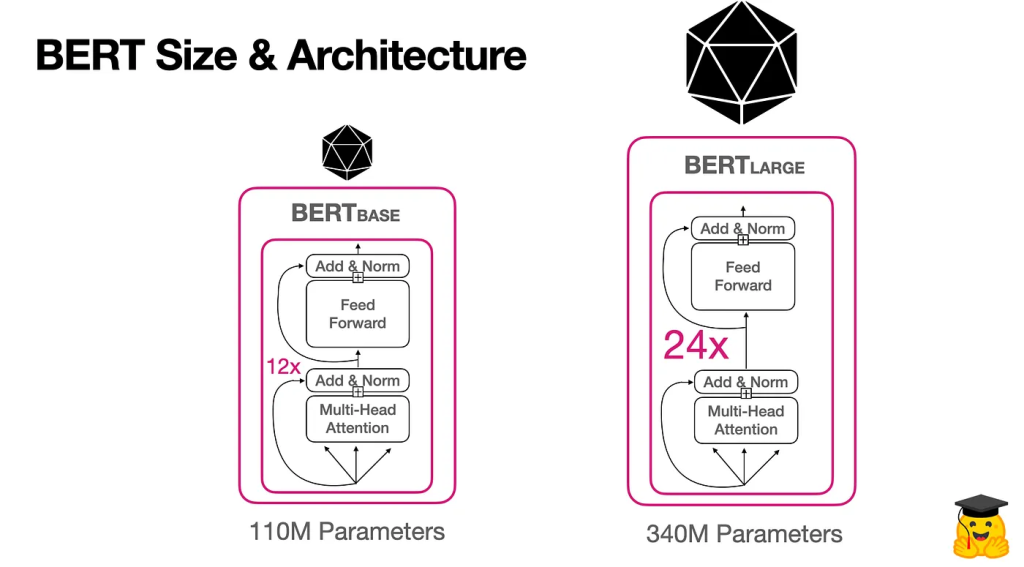
BERT 架构 — 概述
BERT是在像Wikipedia(约25亿个单词)和Google的BooksCorpus(约8亿个单词)这样的大型语料库上进行训练的。这些大型数据集有助于BERT深入观察文本的上下文。然而,研究界开始将LM视为“世界模型”,因为它们还能够构建抽象的关系。
BERT 的架构依赖于 12 个编码器 transformer 层和大约 1.1 亿个参数。为了训练这样的模型,研究团队使用了 64 个 TPU,用了四天时间!
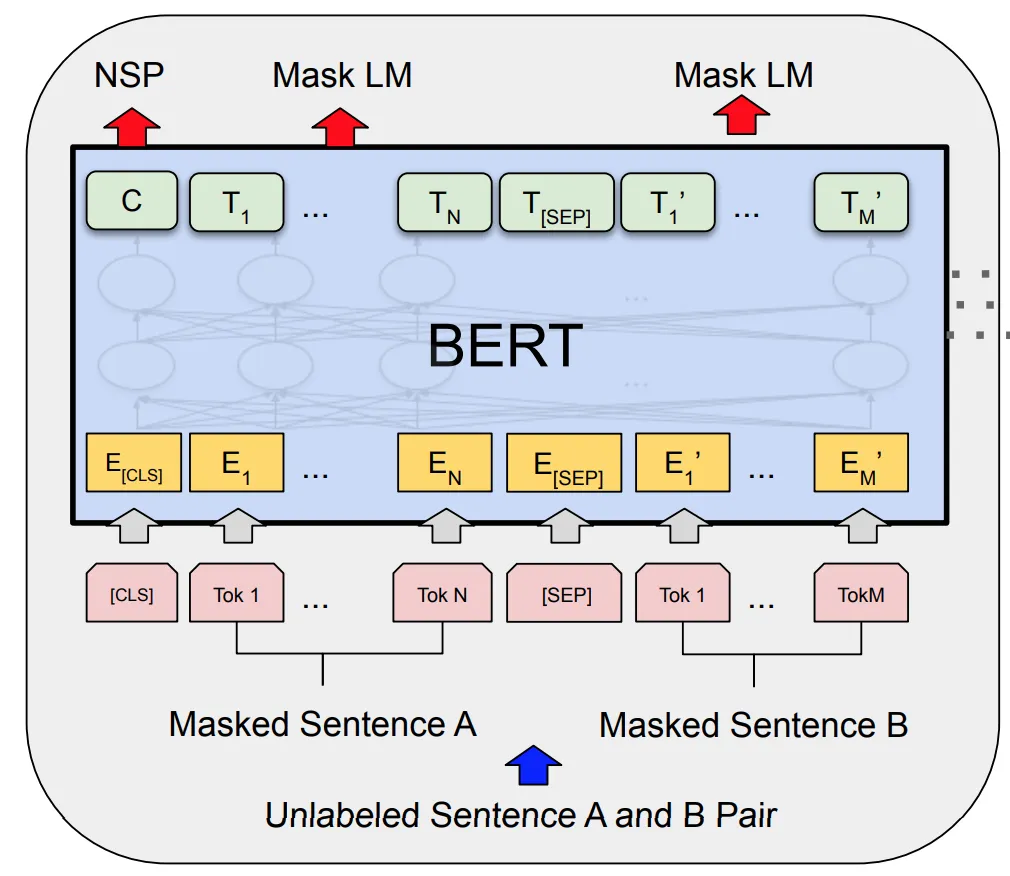
BERT 的训练过程包含两个步骤:
Masked语言模型
在掩码语言模型中,15%的标记化句子被隐藏起来,BERT需要准确地预测这些标记。因此,BERT可以理解它训练的语言(默认是英语)的底层结构。
下一个句子预测
NSP(Next Sentence Prediction)用于教BERT关于句子之间的关系的知识。该模型需要准确预测给定的句子是否跟随前面的句子。
探索数据集
对于该项目,我们将利用“情绪”数据集,其中包含 6 个情绪类别,如下所示:
- anger
- disgust
- fear
- joy
- sadness
- surprise
我们的目标是训练一个分类器模型,能够准确地将一条推文分类到其中一个类别中。
数据集中的类分布
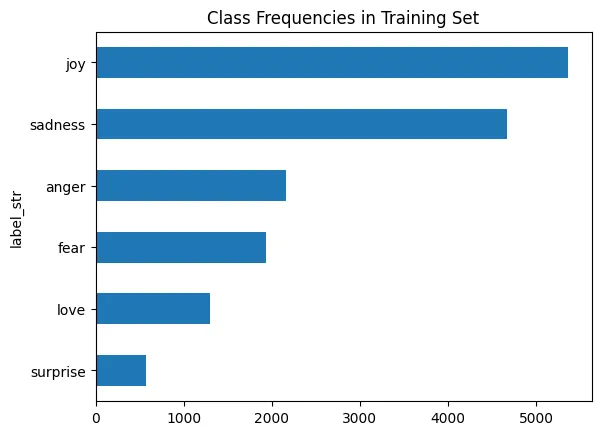
训练集类别分布
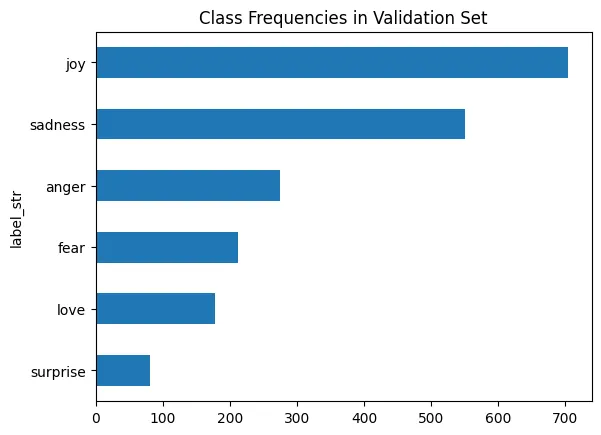
验证集类别分布
处理不平衡类别分布问题
数据集中存在分布不平衡的问题。特别是在‘joy’和‘sadness’类别的样本上更为突出。为了克服不平衡的类别分布,可以采用来自Python的‘imbalanced-learn’库的方法来处理此类问题。该库提供了多种方法来对少数类别进行过采样(ADASYN、SMOTE、随机过采样)或对多数类别进行欠采样(随机欠采样、凝聚最近邻、邻域清理规则)。
理解BERT中的分词过程
基于 Transformer 的模型,如 DistilBERT,需要将输入以 token 化和数值编码的文本形式输入,而不是原始的字符串。
tokenization 涉及将字符串分割成由模型识别的基本单元。存在各种 tokenization 策略,通常通过在数据集中学习获得理想的子词分割。
BERT 使用 Google 研究团队开发的名为“WordPiece”的 tokenization 算法,该算法类似于训练阶段的 BPE(字节对编码)算法,但 tokenization 的实现方式不同。
Text to Tokens
假设我们的输入是“The movie was not good”
Tokens: [‘[CLS]’, ‘the’, ‘movie’, ‘was’, ‘not’, ‘good’, ‘[SEP]’]
Input Indices (encoded text) → [101, 1996, 3185, 2001, 2025, 2204, 102]
BERT或其他的LM希望输入的tokens以数字表示的形式,如上述输入索引。
Note:
- [CLS] Token: Start of the sequence token
- [SEP] Token: End of the sequence token
from transformers import AutoTokenizer
# 载入 Distilbert Tokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
# 编码我们的示例文本
encoded_text = tokenizer("The movie was not good")
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(encoded_text,len(encoded_text.input_ids))
print(tokens){'input_ids': [101, 1996, 3185, 2001, 2025, 2204, 102],
'attention_mask': [1, 1, 1, 1, 1, 1, 1]} 7
['[CLS]', 'the', 'movie', 'was', 'not', 'good', '[SEP]']Training BERT
那些在预训练视觉模型上弄脏手的人应该熟悉一些预训练模型,比如 ResNet、VGG16、Inception-v3、MobileNet 和 EfficientNet。
那些模型通常用作特征提取器,在解决许多视觉模型方面取得了成功,并且可以通过以下两种方式实现:
冻结所有层,只训练分类头,从头开始训练分类头或从现有的头开始训练。
对所有权重进行训练。
BERT和其他LM也可以以相同的方式使用,因为它们已经学习了它们所训练的语言(或语言)的高级特征和表示。
训练方法1:BERT作为特征提取器
在本节中,我将展示如何使用第一种方法训练BERT:冻结BERT的所有层,并将其用作特征提取器。然后在一个或一组分类器上针对这些特征,使用现有标签进行训练。
这种方法采用BERT的最新的隐藏状态提取特征。一旦特征被提取,一个特征矩阵就会被用来创建训练、测试和验证集。
现在让我们动手实践吧,不用担心,我会在我的Kaggle账号中分享所有代码,您可以在文章末尾找到。
加载模型和Tokenizer
from transformers import AutoModel
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device: ",device)
model = AutoModel.from_pretrained(model_ckpt).to(device)提取隐藏状态
# Use whole dataset in Huggingface dataset format
batch = df_source
# Send inputs from CPU to GPU
inputs = {k:v.to(device) for k,v in batch.items()
if k in tokenizer.model_input_names}
# Extract last hidden states
# Disable gradient calculation on PyTorch Side
with torch.no_grad():
last_hidden_state = model(**inputs).last_hidden_state
# Return latest hidden state as numpy matrix
df_hidden = last_hidden_state[:,0].cpu().numpy()创建训练/测试/验证集
import numpy as np
X_train = np.array(df_hidden["train"]["hidden_state"])
X_valid = np.array(df_hidden["valid"]["hidden_state"])
X_test = np.array(df_hidden["test"]["hidden_state"])
y_train = np.array(df_hidden["train"]["label"])
y_valid = np.array(df_hidden["valid"]["label"])
y_test = np.array(df_hidden["test"]["label"])
X_train.shape, y_train.shape训练一个简单的分类器,使用逻辑回归
from sklearn.linear_model import LogisticRegression
clf_lr = LogisticRegression(max_iter=3000)
clf_lr.fit(X_train, y_train)
clf_lr.score(X_valid, y_valid)模型评估
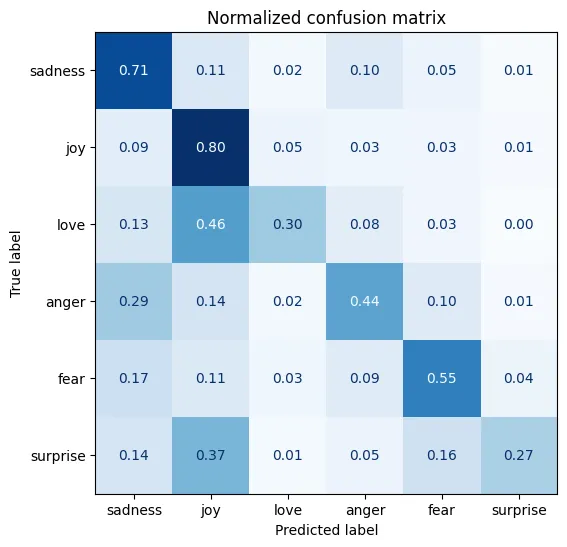
逻辑回归分类器将在测试集上实现 78% 的准确率,这是一个平均但不理想的结果。
我们也可以看到,模型在样本量较少的类别(如恐惧和惊讶)上的表现较差。
然而,通过训练不同的分类器和超参数调整,结果可以更好。
训练方法 2: 微调 BERT
微调 BERT 在 HuggingFace 库的帮助下非常简单。
定义训练参数
# Set Batch Size
batch_size = 64
logging_steps = len(hf_dataset['train']) // batch_size
num_train_epochs = 30
lr_initial = 2e-5
weight_decay = 1e-3
output_dir = ""
training_args = TrainingArguments(output_dir=output_dir,
num_train_epochs=num_train_epochs,
learning_rate=lr_initial,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=weight_decay,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error")注意:您还可以添加提前停止参数,如下所示:
from transformers import EarlyStoppingCallback, IntervalStrategy
args = TrainingArguments(
evaluation_strategy = IntervalStrategy.STEPS, # "steps"
eval_steps = 50, # Evaluation and Save happens every 50 steps
save_total_limit = 5, # Only last 5 models are saved. Older ones are deleted.
metric_for_best_model = 'f1', # Metric to pick the best model
load_best_model_at_end=True,
...
)这些训练参数将允许 HuggingFace Trainer 函数在每个时期之后通过验证集来评估模型。
大多数指标将自动记录在本地Tensorboard中。
期间模型评估的指标
from sklearn.metrics import accuracy_score, f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}Train the Model
# Create Model
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))
model_name = f"models/{model_ckpt}-finetuned-bert-emotion-tweets"
training_args.output_dir = model_name
trainer = Trainer(model=model, args=training_args,
compute_metrics=compute_metrics,
train_dataset=df_encoded["train"],
eval_dataset=df_encoded["validation"],
tokenizer=tokenizer)
trainer.train()
经过2个epochs的训练之后,结果如下:
{'eval_loss': 0.31904336810112, 'eval_accuracy': 0.9025, 'eval_f1': 0.9011653468824986, 'eval_runtime': 1.649, 'eval_samples_per_second': 1212.839, 'eval_steps_per_second': 19.405, 'epoch': 1.0}
{'loss': 0.2464, 'learning_rate': 0.0, 'epoch': 2.0}
{'eval_loss': 0.2177528589963913, 'eval_accuracy': 0.9215, 'eval_f1': 0.9215056955967161, 'eval_runtime': 1.8332, 'eval_samples_per_second': 1090.98, 'eval_steps_per_second': 17.456, 'epoch': 2.0}
{'train_runtime': 98.2367, 'train_samples_per_second': 325.744, 'train_steps_per_second': 5.09, 'train_loss': 0.5314080963134765, 'epoch': 2.0}Error Analysis
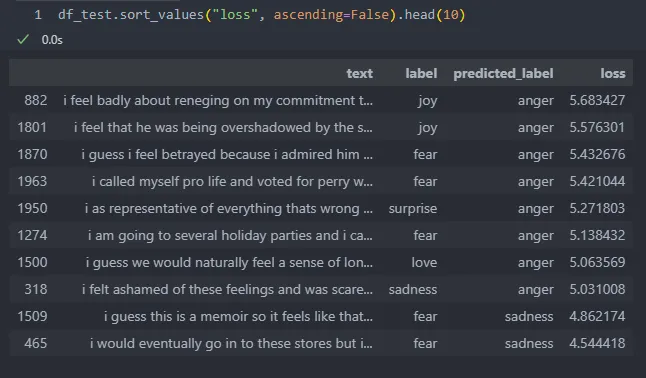
让我们按升序对一些预测进行排序,以分析模型为什么无法正确地对其进行分类: